ProseCreator: A Tri-Store Knowledge Architecture for AI-Assisted Long-Form Creative Writing
Comprehensive research paper covering ProseCreator's tri-store memory architecture (Neo4j + Qdrant + GraphRAG), living blueprints with drift detection, 10-dimensional continuity validation, genre-adaptive anti-AI detection, and horizontally scalable workflow dispatch via WorkflowJobDispatcher. Includes competitive analysis against Sudowrite, NovelAI, Jasper, and Writesonic.
ProseCreator: A Tri-Store Knowledge Architecture for AI-Assisted Long-Form Creative Writing with Living Blueprints, Multi-Dimensional Continuity Validation, and Horizontally Scalable Workflow Dispatch
Adverant Research Team Adverant, Ltd.
Abstract
Maintaining narrative coherence across novel-length manuscripts (100,000+ words) remains one of the most demanding challenges in AI-assisted creative writing. Existing systems typically rely on sliding context windows or shallow retrieval mechanisms that degrade as manuscript length increases, producing inconsistencies in character behavior, plot logic, and narrative voice that compound across chapters. We present ProseCreator, a production-deployed platform that addresses these limitations through a tri-store knowledge architecture combining PostgreSQL (94 migrations, 91+ relational tables), Neo4j 5.x (10 node types, 16 relationship types), and Qdrant (4 vector collections at 1536, 1024, and 768 dimensions), unified by a GraphRAG semantic memory layer. The system implements a nine-layer parallel context injection pipeline that assembles narrative context in under 500 milliseconds, a ten-dimensional continuity validation framework that operates on generated content in parallel, and an eleven-point voice consistency checker grounded in psychological profiling including Big Five personality integration. Content humanization is achieved through fifteen algorithmic techniques with twelve genre-specific profiles, targeting less than five percent AI detection probability. A two-tier workflow dispatch architecture routes 48 distinct job types across seven logical queues to an external workflow execution engine, enabling horizontal pod scaling without in-process job state. We describe the living blueprint system that evolves story structure in response to narrative divergence, the series intelligence module that maintains cross-book coherence across one million or more words spanning ten or more books, and the constitutional AI framework that encodes author intent as structured system prompt prefixes. The platform exposes 55 REST API route modules and serves twelve specialized format generators spanning novel, screenplay, poetry, comic book, podcast, and academic writing modes.
Keywords: AI-assisted creative writing, knowledge graph, narrative coherence, multi-agent orchestration, vector search, workflow dispatch, anti-AI detection, long-form generation
1. Introduction
The aspiration to automate or assist in creative writing is nearly as old as computing itself. From early experiments with Markov chains and context-free grammars to the transformer revolution inaugurated by Vaswani et al. (2017), the field has steadily advanced toward systems capable of generating fluent, stylistically varied prose. The emergence of large language models (LLMs) such as GPT-4 (OpenAI, 2023) and Claude (Anthropic, 2024) has brought this aspiration tantalizingly close to practical realization. These models can produce paragraphs of remarkable quality in isolation. The difficulty lies not in generating a single paragraph but in generating the ten-thousandth paragraph of a manuscript while maintaining fidelity to everything that came before.
This problem---narrative coherence at scale---is qualitatively different from the generation tasks that dominate current research benchmarks. A short story of 5,000 words can reasonably fit within a single context window. A novel of 100,000 words cannot. A ten-book fantasy series exceeding one million words presents challenges that are not merely quantitative but structural: characters must age consistently, subplots introduced in Book 2 must resolve by Book 7, the magical system established in the first chapter must constrain events in the last, and each character's dialogue must remain psychologically consistent across hundreds of scenes. The context window, however large, is fundamentally the wrong abstraction for this problem. What is needed is structured, queryable knowledge that can be assembled on demand.
The fundamental tension in AI-assisted creative writing is between creative freedom and narrative consistency. An author writing with AI assistance wants the system to surprise them, to suggest directions they had not considered, to produce prose that feels alive rather than mechanical. Simultaneously, that same author requires absolute fidelity to established facts: a character who lost their left hand in Chapter 3 must not gesture with it in Chapter 12. These requirements are in productive tension. The system must be creative within constraints, and the constraints must be both comprehensive and dynamically updated as the story evolves.
Existing commercial tools approach this problem from different directions. Sudowrite (2024) mirrors tone and tracks plot threads using a multi-model stack, but its continuity guarantees weaken significantly beyond the short-novel range. NovelAI (2024) offers fine-tuned models with powerful stylistic controls but lacks structured knowledge representation for long-form coherence. Jasper and Writesonic focus on marketing and content writing rather than narrative fiction. None of these systems provides the combination of graph-structured character relationships, vector-indexed voice fingerprints, semantic memory with hybrid retrieval, and formally specified world rules that long-form fiction demands.
The academic literature on story generation has made significant progress in recent years. The DOC framework (Yang et al., 2023) demonstrated that hierarchical outlines improve plot coherence by shifting creative responsibility from the drafting stage to the planning phase. DOME (Wang and Hu, 2024) introduced dynamic hierarchical outlining with memory enhancement, fusing planning and writing stages to maintain coherence under the uncertainty inherent in sequential generation. The SCORE system (2025) achieved notable improvements in coherence through modular knowledge graph construction for persistent story memory. Multi-agent approaches to story generation (ACL 2025) have shown promise for character simulation, though typically at the short-story rather than novel scale.
Yet a significant gap remains between academic prototypes and production-grade systems that must handle real authors working on real manuscripts over weeks and months. The prototype can afford to regenerate from scratch; the production system must incrementally extend a manuscript that represents hundreds of hours of human creative effort. The prototype operates on synthetic benchmarks; the production system must handle the full messiness of human creative intent, including retroactive plot changes, character renaming, and the author's evolving understanding of their own story.
This paper presents ProseCreator, a production-deployed platform that bridges this gap. Our key contributions are:
-
A tri-store knowledge architecture that combines relational state (PostgreSQL), graph relationships (Neo4j), and vector similarity (Qdrant) with a unifying GraphRAG semantic layer, enabling different retrieval strategies optimized for different aspects of narrative coherence.
-
A nine-layer parallel context injection pipeline that assembles comprehensive narrative context from all three stores in under 500 milliseconds via
Promise.all(), with smart truncation under an 8,000-token budget using a priority cascade. -
A ten-dimensional continuity validation framework that checks generated content against character states, location logic, plot thread advancement, world rules, timeline ordering, voice consistency, tone, trope execution, and world element coherence---all in parallel.
-
A living blueprint system that detects divergence between planned and actual narrative content, automatically evolving story structure with significance-threshold gating to prevent unnecessary regeneration.
-
A two-tier workflow dispatch architecture that routes 48 distinct job types across seven logical queues to an external workflow engine, eliminating all in-process job state and enabling truly stateless horizontal scaling.
-
A fifteen-technique humanization pipeline with twelve genre-specific profiles, addressing the growing concern of AI-generated content detection in creative markets.
The remainder of this paper is organized as follows. Section 2 surveys related work in AI-assisted creative writing, knowledge graphs for narrative, multi-agent generation, and workflow orchestration. Section 3 describes the overall system architecture. Section 4 presents the tri-store memory architecture in detail. Section 5 covers the living blueprint system. Section 6 describes the content generation pipeline. Section 7 discusses story architecture features. Section 8 details the workflow dispatch architecture. Section 9 analyzes horizontal scalability. Section 10 covers the multi-format export pipeline. Section 11 provides evaluation and comparative analysis. Section 12 discusses limitations, and Section 13 concludes with future directions.
2. Background and Related Work
2.1 AI-Assisted Creative Writing Systems
The intersection of artificial intelligence and creative writing has attracted sustained research interest since the earliest days of computational linguistics. Rule-based systems gave way to statistical approaches, which in turn yielded to neural methods. The transformer architecture (Vaswani et al., 2017) marked a decisive transition, enabling language models of unprecedented fluency.
Google's Wordcraft (Yuan et al., 2022) represents a landmark in human-AI co-writing research. Developed as a text editor in which users collaborate with a generative language model, Wordcraft demonstrated that LLMs enable novel co-writing experiences where the model can engage in open-ended conversation about the story and respond to writers' custom requests expressed in natural language. The user study showed that participants made more requests and incorporated more AI suggestions when using Wordcraft, and writers who found the LLM helpful reported greater enjoyment and ease. However, Wordcraft was designed for short story writing and did not address the structural challenges of novel-length manuscripts.
More recent work has focused specifically on long-form generation. Wang and Hu (2024) proposed DOME (Dynamic Hierarchical Outlining with Memory-Enhancement), which generates long-form stories with coherent content and plot by incorporating writing theory into outline planning and fusing plan and writing stages. The dynamic hierarchical outline mechanism adapts to the uncertainty of previously generated content, improving plot completeness. Measuring information distortion in hierarchical ultra-long novel generation, Zhao et al. (2025) examined the optimal expansion ratio for maintaining coherence at the million-word scale, finding that challenges at this scale are "qualitatively and quantitatively different" from those at shorter lengths.
The SCORE system (Story Coherence and Retrieval Enhancement for AI Narratives) achieved 23.6% higher coherence on the NCI-2.0 benchmark, 89.7% emotional consistency, and 41.8% fewer hallucinations versus baseline GPT models through modular knowledge graph construction for persistent story memory. This result validates our architectural intuition that structured knowledge representation is essential for narrative coherence.
A multi-agent framework for long story generation (ACL 2025) demonstrated that character simulation through specialized agent roles can improve narrative quality, particularly in dialogue consistency and character development. This approach influenced our MageAgent orchestration design, though our implementation extends it to encompass 50 specialized agent roles operating across the full generation pipeline.
2.2 Knowledge Graphs for Narrative Representation
Knowledge graphs have emerged as a natural representation for the structured relationships that underlie narrative fiction. Characters know other characters, inhabit locations, participate in events, and drive plot threads---all fundamentally graph-structured relationships that are poorly served by flat text or even vector embeddings alone.
Guan et al. (2025) demonstrated that knowledge graphs can systematically track story elements, mitigating hallucination and reinforcing narrative coherence in LLM-based storytelling. Their KG-assisted storytelling pipeline was evaluated through a user study showing measurable improvements in narrative quality and enabling user-driven modifications to the story structure.
The StoRM framework (Guiding Neural Story Generation with Reader Models, Brahman et al., 2021) used a reader model to reason about story progression by inferring what humans believe about concepts, entities, and relations in the fictional world, represented as a knowledge graph. This approach demonstrated that knowledge graph representations afford story coherence by making the model's world state explicit and queryable.
Narrative Graph (Li et al., 2023) proposed event-centric temporal knowledge graphs for telling evolving stories, representing news documents as graphs and compressing them into salient complex events in temporal order. While focused on journalism rather than fiction, the temporal ordering and event-centric approach directly informed our timeline validation and event node design in Neo4j.
The integration of knowledge graphs with vector search represents a particularly promising direction. GraphRAG approaches combining Neo4j and Qdrant have demonstrated 20--25% accuracy improvements in retrieval-augmented generation tasks across regulated domains (Lettria, 2024). Our tri-store architecture extends this hybrid approach to the creative writing domain, where the graph captures narrative structure while vectors capture semantic similarity and stylistic fingerprints.
2.3 Multi-Agent Content Generation
The use of multiple specialized agents for complex content generation has gained significant traction. Multi-Agent Collaboration Mechanisms: A Survey of LLMs (Zhang et al., 2025) characterizes collaboration mechanisms along key dimensions including actors, types (cooperation, competition, coopetition), structures (peer-to-peer, centralized, distributed), strategies (role-based, model-based), and coordination protocols.
Unlike traditional multi-agent systems that rely on predefined protocols, LLM-based systems leverage natural language as a universal medium for coordination, enabling unprecedented flexibility and emergent behaviors. AgentsNet (2025) proposed coordination and collaborative reasoning benchmarks for multi-agent LLMs, probing up to 100 agents. These findings informed our dual-path AI integration strategy: MageAgent for multi-agent consensus on complex tasks (requiring 5--7 minutes but producing higher-quality results through agent deliberation) and ClaudeDirectClient for fast single-agent generation (30--120 seconds) with automatic fallback between the two paths.
2.4 Retrieval-Augmented Generation
SQL3 linesThe foundational work on Retrieval-Augmented Generation by Lewis et al. (2020) established that combining pre-trained parametric memory with non-parametric memory accessed through neural retrieval produces more specific, diverse, and factual language generation. RAG models address the fundamental limitation that large pre-trained models have restricted ability to access and precisely manipulate knowledge, and that providing provenance for decisions and updating world knowledge remain open challenges. Our GraphRAGClient implements a four-stack memory model (memories, episodes, documents, patterns) that extends the RAG paradigm to creative writing. Rather than retrieving from a static knowledge base, our system maintains a continuously updated memory that grows with each generated beat, creating a feedback loop where generated content enriches the retrieval corpus for subsequent generation.
2.5 AI-Generated Text Detection and Humanization
The proliferation of AI-generated content has spurred rapid development of detection systems, which in turn has motivated research into humanization techniques. Shi et al. (2024) demonstrated that well-trained text detectors have vulnerabilities to adversarial attacks including paraphrasing, highlighting the necessity for resilient detection methods. Their framework for adversarial attacks performs minor perturbations in machine-generated content to evade detection in both white-box and black-box settings, showing that detection models can be compromised in as few as ten seconds.
The creative writing domain faces particular challenges in this area. Authors using AI assistance for legitimate creative purposes may find their work flagged by detection systems, creating a practical need for content that reads as authentically human. Our AntiAIDetection module addresses this through fifteen algorithmic techniques organized by linguistic dimension (vocabulary, syntax, rhythm, emotion, dialogue) with twelve genre-specific profiles that encode the distinctive patterns of human writing in each genre.
2.6 Workflow Orchestration and Horizontal Scaling
The architectural challenge of executing long-running AI workloads (90--300 seconds per generation job) within a web-serving process has driven interest in decoupled execution architectures. Horizontal pod autoscaling in Kubernetes for elastic container orchestration (Nguyen and Yeom, 2020) established foundational patterns for auto-scaling containerized services based on CPU and memory metrics. More recent work on resource-efficient reactive and proactive auto-scaling for microservice architectures (2025) extends these patterns with AI-driven demand forecasting.
The distributed job scheduler pattern---decoupling scheduling decisions from job execution to allow independent scaling of the scheduling logic and the worker fleet (Burns et al., 2016)---directly informed our WorkflowJobDispatcher design. By routing all 48 job types to an external workflow engine (Nexus Workflows), ProseCreator pods remain stateless and horizontally scalable without session affinity requirements.
3. System Architecture
3.1 Architectural Overview
ProseCreator is deployed as a Kubernetes-managed microservice within the Nexus platform, an enterprise AI orchestration system. The architecture follows a layered design separating client interfaces, API routing, business logic, AI integration, and data persistence. Figure 1 illustrates the complete system architecture.
 Figure 1. ProseCreator system architecture showing the layered design from client interfaces through the service layer to the tri-store persistence tier.
Figure 1. ProseCreator system architecture showing the layered design from client interfaces through the service layer to the tri-store persistence tier.
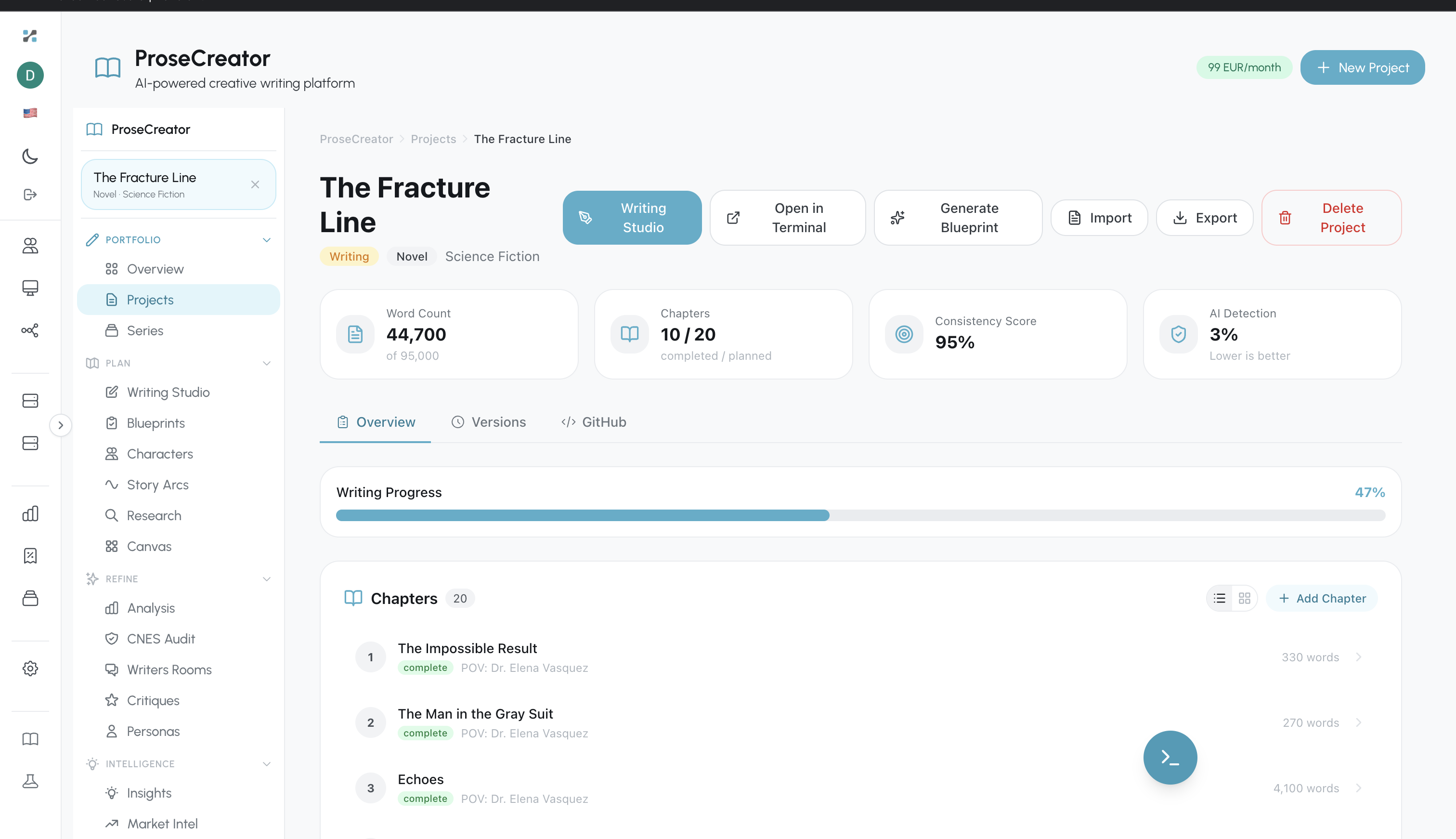 Figure 1a. ProseCreator project dashboard showing "The Fracture Line" novel --- 44,700 words, 10/20 chapters, 95% consistency score, 3% AI detection rate.
Figure 1a. ProseCreator project dashboard showing "The Fracture Line" novel --- 44,700 words, 10/20 chapters, 95% consistency score, 3% AI detection rate.
The server component is built on Express.js 4.x with TypeScript 5.3+ in strict mode, running on Node.js 20+. It exposes two network interfaces: an HTTP server on port 9099 for REST API traffic and a WebSocket server on port 9100 for real-time streaming during content generation. In Kubernetes, a port override sets the internal container port to 3000.
3.2 API Surface
The REST API is organized into 55 route modules under the base path /prosecreator/api, making it one of the more expansive API surfaces in the creative writing tool space. Route modules span the full lifecycle of creative writing from project creation and series management through content generation, analysis, critique, publication, and export. Each route module receives services via req.app.locals.services, following the dependency injection pattern established by the ServiceContainer.
Key route categories include:
- Content lifecycle: projects, series, chapters, blueprints, generation, characters, beats
- Analysis and critique: analysis, critiques, personas, rooms, insights, inspector
- Story architecture: plot-threads, tropes, world-building, character-evolution, story-forge
- Publication: export (DOCX/EPUB/PDF), publication, marketing, citations
- Infrastructure: health, operations, internal-jobs, workflows, tools, modes
- Collaboration: editor-sync, comments, tracked-changes, canvas, handoffs
All API inputs undergo Zod validation at system boundaries, and authentication is enforced via JWT tokens with tier-based rate limiting backed by Redis.
3.3 ServiceContainer: Dependency Injection Root
The ServiceContainer class serves as the dependency injection root, instantiating all services in the correct dependency order during application startup. This single class manages the lifecycle of:
- 52 repository classes providing typed access to PostgreSQL tables across the
proseschema - 41 service classes implementing business logic for content generation, analysis, blueprint management, publication, and more
- 15 job handler classes that process callback results from Nexus Workflows
- Infrastructure clients for Neo4j (graph database), Qdrant (vector search), GraphRAG (semantic memory), and Redis (caching and rate limiting)
- AI integration clients including MageAgentClient (multi-agent orchestration), ClaudeDirectClient (single-agent proxy), and GeminiCoverService (image generation)
The container pattern ensures that services are constructed exactly once and in the correct order---the MemoryManager, for instance, must be constructed after the GraphRAGClient, Neo4jClient, and QdrantClient it depends on, but before the ContextInjector that consumes it.
3.4 Database Layer
The data layer comprises four persistence systems, each chosen for its particular strengths:
PostgreSQL serves as the relational state of truth. The prose schema has grown to 91+ tables across 94 migrations, covering every domain concept from projects and chapters to tropes, world elements, ingestion pipelines, and the writing studio registry (20 writing modes, 26 inspector panels, 138 slash commands, seeded by database migrations 025--032). PostgreSQL handles all transactional operations, job tracking, version control, and the bulk of read queries.
Neo4j 5.x provides graph-structured knowledge about narrative relationships. The schema defines 10 node labels (Project, Series, Character, Location, PlotThread, Event, Chapter, Beat, Canvas, CanvasNode) and 16 relationship types (BELONGS_TO, KNOWS, APPEARS_IN, INVOLVES, OCCURS_IN, LOCATED_AT, FOLLOWS, EVOLVES_FROM, DEVELOPS, CONTAINS, PART_OF, PARTICIPATES_IN, CONTAINS_IDEA, IDEA_LINKED, IDEA_CONNECTS, SPAWNED_FROM). The DEVELOPS relationship is particularly important for plot thread dependency tracking, enabling Cypher traversals that identify plot threads that depend on other threads.
Qdrant provides vector similarity search across four specialized collections: prose_content_embeddings (1536-dimensional, for semantic search over generated beats and chapters), prose_character_voices (1024-dimensional, for character voice fingerprinting and dialogue matching), prose_metadata_embeddings (768-dimensional, for fast metadata and title search), and prose_canvas_ideas (768-dimensional, for IdeaForge canvas node clustering and suggestions). Each collection has optimized HNSW configuration for its access pattern.
Redis serves two functions: rate limiting via express-rate-limit with rate-limit-redis (ensuring consistent rate enforcement across multiple pods) and short-lived caching of frequently accessed data.
These four systems are unified by the GraphRAG HTTP API, which provides a semantic memory layer with four memory stacks: memories (episodic recall), episodes (session summaries), documents (ingested content with automatic chunking), and patterns (recurring narrative patterns). The GraphRAGClient communicates via tenant-scoped headers (X-Company-ID, X-App-ID, X-User-ID) for multi-tenant isolation.
4. Tri-Store Memory Architecture
The memory architecture is the intellectual core of ProseCreator. It solves the fundamental problem of maintaining narrative coherence at scale by combining three complementary storage paradigms---relational, graph, and vector---into a unified system that can answer different types of queries with the appropriate retrieval strategy.
4.1 GraphRAGClient
The GraphRAGClient (located at src/memory/GraphRAGClient.ts) provides a robust HTTP interface to the GraphRAG semantic memory service. It implements four memory stacks:
-
Memories: Episodic memories of past events, decisions, and outcomes within the story world. These are stored with rich metadata and can be retrieved by semantic similarity or explicit query.
-
Episodes: Session-level summaries that capture the causal chains of writing sessions---what was planned, what was generated, how the story evolved during a particular writing session.
-
Documents: Full-text documents with automatic chunking for retrieval. When a beat is generated, its content is stored as a GraphRAG document, making it available for semantic search by future generation calls.
-
Patterns: Recurring narrative patterns extracted from the manuscript, such as a character's tendency toward particular emotional responses or the author's preferred pacing structures.
The client implements automatic retry with exponential backoff (configurable, default 3 attempts with 1-second base delay) and comprehensive error handling. All requests include tenant context headers for multi-tenant isolation: X-Company-ID: adverant, X-App-ID: prosecreator, with X-User-ID set per-request.
4.2 MemoryManager: Triple-Store Orchestration
The MemoryManager class (1,000+ lines at src/memory/MemoryManager.ts) orchestrates write operations across all three stores. When a beat is generated, the MemoryManager executes a triple write:
-
Qdrant vector store: The beat's embedding vector (1536-dimensional) is stored alongside a rich metadata payload including
project_id,chapter_number,beat_number,content_type,word_count,characters_present(array),plot_threads(array),emotional_tone,pov_character, andlocation. This enables fast similarity search for finding contextually related beats. -
GraphRAG semantic document: The beat's full text content is stored as a document with metadata, where the GraphRAG service handles automatic chunking for retrieval. The tenant headers ensure per-user isolation.
-
Neo4j graph relationships: Character appearances (
APPEARS_IN), plot thread involvement (INVOLVES), and location associations (OCCURS_IN) are recorded as typed relationships with properties including chapter numbers, significance levels, and emotional states.
This triple write ensures that each piece of generated content is immediately available through three different retrieval strategies: vector similarity (finding similar passages by semantic meaning), graph traversal (finding all scenes where two characters interact, or tracking a plot thread across chapters), and semantic search (natural language queries against the full manuscript memory).
The MemoryManager implements an LRU cache with configurable TTL (default 5 minutes) and maximum size (default 1,000 items). Cache hits are tracked alongside misses, with periodic cleanup every 60 seconds evicting expired entries.
4.3 ContextInjector: Nine-Layer Parallel Context Assembly
The ContextInjector class (961 lines at src/memory/ContextInjector.ts) is responsible for assembling comprehensive narrative context before each beat generation. Its design is optimized for latency: all nine context layers are retrieved in parallel via Promise.all(), targeting total assembly time under 500 milliseconds.
The nine context layers are:
-
Recent beats (last 5): Direct retrieval from PostgreSQL, providing immediate narrative continuity.
-
Character contexts: For each character present in the blueprint, the system retrieves profiles, relationships (via Neo4j
KNOWStraversals), and recent mentions (via Qdrant similarity search). This produces rich character dossiers including current emotional state and relationship dynamics. -
Plot thread contexts: Active plot thread states, dependency chains (via Neo4j
DEVELOPSrelationships), and predicted next developments computed by a state machine (introduced → developing → active → resolved). The state machine predicts likely narrative developments based on thread type and current status. -
Location contexts: Physical setting details retrieved from Neo4j, including hierarchical location relationships via
CONTAINS. -
Similar beats: Past beats with similar narrative function retrieved via GraphRAG semantic search. This enables stylistic consistency---if previous tension-building beats in this project used short sentences and body-first emotion, the system can present those examples to the generation model.
-
Project constitution: A six-section structured document encoding author intent: creative vision, voice and tone, content rules, legal compliance, thematic guardrails, and style directives. Retrieved from PostgreSQL and injected as a system prompt prefix, making it more authoritative than style profiles.
-
Series constitution: Universe-level guidelines that apply across all books in a series, ensuring shared-world consistency.
-
Active tropes: Currently active trope assignments for the target chapter, including execution modifiers. ProseCreator supports eleven execution modifiers (played straight, subverted, deconstructed, lampshaded, invoked, zigzagged, exploited, justified, reconstructed, implied, double subverted), each with LLM-facing guidance instructions.
-
World elements: The top 20 world-building elements by importance tier (critical/major), including magic systems, natural laws, technologies, religions, and cultural norms. These serve as hard constraints on generated content.
For non-fiction writing modes (digital, academic, professional, instructional, performance), the injector automatically skips fiction-specific context layers (characters, plot threads, locations, tropes, world elements), avoiding irrelevant context pollution.
After parallel retrieval, the ContextInjector runs the ContinuityEngine on the assembled context to generate pre-generation warnings. It then estimates the total token count (using the approximation of 1 token per 4 characters) and applies smart truncation if the context exceeds the 8,000-token budget. Truncation follows a priority cascade: continuity warnings have highest priority (never truncated), followed by recent beats, characters, tropes, plot threads, world elements, similar beats, and finally locations.
Figure 2 illustrates the complete write and read paths through the tri-store architecture.
 Figure 2. Tri-store memory architecture showing parallel write paths (left) and nine-layer parallel read path with smart truncation (right).
Figure 2. Tri-store memory architecture showing parallel write paths (left) and nine-layer parallel read path with smart truncation (right).
4.4 ContinuityEngine: Pre-Generation Validation
The ContinuityEngine (1,458 lines at src/memory/ContinuityEngine.ts) runs pre-generation validation checks on the assembled context. It operates in parallel via Promise.all(), executing four major check categories:
-
Character consistency: Validates age progression (no character should age backward), detects dead character resurrection (characters marked as dead in Neo4j should not appear alive), checks for role demotion (a protagonist should not silently become a background character), and verifies relationship states match the most recent interactions.
-
Plot thread consistency: Identifies unresolved threads that have been dormant for more than three chapters (configurable threshold), tracks foreshadowing element payoff (foreshadowing introduced in earlier chapters should eventually be paid off or explicitly subverted), and detects contradictory thread states.
-
Timeline logic: Validates temporal ordering of events, checks character travel times (a character cannot be in Paris in one scene and Tokyo in the next without a time gap), and verifies that cause-effect relationships respect temporal ordering.
-
Location logic: Detects character teleportation (appearing at a location without having traveled there), validates hierarchical location consistency (a character cannot be in a room within a building if they have not entered the building), and checks physical impossibilities.
Each check produces warnings with severity levels (critical, high, medium, low). Critical warnings are surfaced prominently to the generation model, directing it to avoid the flagged inconsistency. The target is a 98%+ continuity score, computed as a weighted reduction from a perfect 1.0 baseline based on warning counts and severities.
4.5 SeriesIntelligence: Cross-Book Coherence
The SeriesIntelligence class (1,034 lines at src/memory/SeriesIntelligence.ts) extends the memory architecture to span entire book series exceeding one million words. Its design enables the use case of importing books 1 through 9 of a series and writing book 10 with perfect continuity.
Series context retrieval targets a latency of under 2 seconds for a series with 10 books, achieved through parallel retrieval of six data categories:
-
Character arcs: How each character has evolved across the series, tracking first appearance, key transformation moments, and current state per book.
-
Plot thread lifecycles: The complete lifecycle of each thread from introduction through resolution, tracked with
intro_bookandresolved_bookmarkers. Unresolved threads from earlier books are flagged as candidates for continuation or deliberate abandonment. -
Series lore: Accumulated world-building knowledge retrieved via GraphRAG hybrid retrieval (combining semantic search with structured graph queries).
-
Timeline events: Chronological event ordering across all books in the series, enabling temporal consistency validation.
-
Universe rules: Explicit constraints on the story world (e.g., "magic requires line of sight," "faster-than-light travel is impossible") extracted from the series constitution and enforced during generation.
-
Dangling thread detection: Automatic identification of plot threads, character arcs, and foreshadowing elements that were introduced but never resolved across the series.
5. Living Blueprint System
5.1 Blueprint Generation
The BlueprintGenerator produces multi-act story structures that serve as the skeleton for generation. A project blueprint encompasses:
-
Act structure: Multi-act frameworks (typically three or five acts) with beat-level granularity, where each beat specifies a narrative function (action, dialogue, description, transition, internal monologue), characters present, plot threads active, target word count, emotional tone, and pacing directive.
-
Pacing curves: Per-chapter pacing specifications with concrete generation guidance. The PromptBuilder translates abstract pacing labels into quantitative targets: "slow" means 15--25 word average sentences in 4--8 sentence paragraphs with detailed scene-setting; "fast" means 5--12 word sentences in 1--3 sentence paragraphs with clipped dialogue and cut transitions.
- **Character involvement matrices**: Which characters appear in which chapters, with what significance level (major, minor, mentioned, cameo).
- **Emotional arcs**: Chapter-level emotional trajectories (rising, falling, stable, climax, resolution) that guide the tone of generated content.
- Dramatic function assignments: Each beat receives a specific dramatic purpose (e.g., "introduce the antagonist's motivation," "escalate the romantic tension," "deliver the midpoint reversal").
Blueprints are generated at three levels of hierarchy: series blueprints (spanning multiple books), project blueprints (single-book structure), and chapter blueprints (beat-level granularity within a chapter).
5.2 Blueprint Evolution
The BlueprintEvolver (at src/blueprint/BlueprintEvolver.ts) addresses a fundamental challenge: stories diverge from their outlines. Characters take unexpected turns, new plot threads emerge organically from the writing, and the author's understanding of their own story evolves. A static blueprint becomes a liability rather than an asset once it diverges significantly from the actual manuscript.
The evolver analyzes divergences between the planned blueprint and actual completed beats, categorizing changes into six update categories:
- Character arcs: A character has developed differently than planned (e.g., a planned villain shows sympathetic qualities).
- Plot threads: New threads have emerged or planned threads have been abandoned.
- Foreshadowing: Elements have been planted in the manuscript that the blueprint did not anticipate.
- Relationships: Character relationships have evolved in unplanned directions.
- World-building: The story has established world details not present in the original blueprint.
- Future chapters: The implications of current divergences for upcoming chapter plans.
Divergence analysis is performed by the MageAgent multi-agent orchestration system, with automatic fallback to ClaudeDirectClient if MageAgent is unavailable. A significance threshold of 0.5 gates blueprint updates: only divergences exceeding this threshold trigger regeneration of future chapter blueprints, preventing unnecessary churn.
5.3 Blueprint Management
The BlueprintManager handles the lifecycle of blueprints including version control (blueprints are versioned in PostgreSQL with full history), GraphRAG document persistence (enabling semantic search across blueprint versions), and the series-to-project-to-chapter hierarchy.
The living blueprint concept is realized through a feedback loop: the blueprint guides generation, generation produces content, the evolver detects divergence between plan and reality, and significant divergences trigger blueprint updates that guide subsequent generation. This loop operates continuously throughout the writing process, ensuring that the blueprint remains a useful planning tool rather than an outdated artifact.
6. Content Generation Pipeline
6.1 ProseGenerator: Main Orchestration
The ProseGenerator class (at src/generation/ProseGenerator.ts) orchestrates the complete content generation pipeline. A single beat generation follows this sequence:
- Context injection (ContextInjector): Assemble nine-layer parallel context.
- Prompt construction (PromptBuilder): Build mode-adaptive prompts with constitution guidelines.
- AI generation (AgentOrchestrator or ClaudeDirectClient): Produce draft content.
4. **Humanization** (AntiAIDetection): Apply fifteen techniques plus genre-specific rules.
5. **Continuity validation** (ContinuityValidator): Ten parallel validation checks.
6. **Voice consistency** (VoiceConsistency): Eleven-point psychological validation.
7. **Memory storage** (MemoryManager): Triple-write to Qdrant, GraphRAG, and Neo4j.
This pipeline ensures that no generated content reaches the user without passing through validation and humanization. The entire pipeline is illustrated in Figure 3.
 Figure 3. Seven-stage content generation pipeline showing the flow from context injection through AI generation, humanization, validation, and memory persistence.
Figure 3. Seven-stage content generation pipeline showing the flow from context injection through AI generation, humanization, validation, and memory persistence.
6.2 PromptBuilder: Mode-Adaptive Prompt Construction
The PromptBuilder (944 lines at src/generation/PromptBuilder.ts) constructs prompts tailored to thirteen distinct writing formats: novel, screenplay, poetry, technical, academic, how-to, content, speech, podcast, comic book, stageplay, fiction, and YouTube. Each format defines:
- System role: The persona the AI adopts (e.g., "You are a literary fiction author known for psychological depth" vs. "You are a YouTube scriptwriter optimizing for audience retention").
- Focus areas: What aspects of the writing to prioritize (e.g., character interiority for literary fiction vs. visual scene description for screenplay).
- Style guidelines: Format-specific prose conventions (e.g., Fountain formatting rules for screenplay, meter and rhyme constraints for poetry).
- Constraints: Hard limits on the generated output (e.g., word count targets, formatting requirements).
- Quality criteria: How to evaluate the output (e.g., "dialogue must advance both plot and character" vs. "each stanza must maintain consistent meter").
The prompt is assembled from six components: system prompt, context prompt (from ContextInjector), task prompt (specific beat instructions), style prompt, constraints prompt, and optional examples prompt. Constitution guidelines are injected as a system prompt prefix, making them stronger than per-beat style instructions.
Pacing guidance is particularly noteworthy. Rather than passing abstract labels like "fast" to the generation model, the PromptBuilder converts pacing directives into quantitative targets with concrete writing guidance:
- Slow: "Use longer, flowing sentences (15-25 words avg). Include detailed scene-setting, introspection, sensory descriptions. Paragraphs 4-8 sentences."
- Fast: "Short, punchy sentences (5-12 words avg). Favor action verbs, minimal description. 1-3 sentence paragraphs. Cut transitions, jump between beats. Clipped dialogue."
Trope execution guidance is injected when active tropes are assigned to the target chapter. Each of the eleven execution modifiers produces specific LLM instructions (e.g., "Subverted: Set up expectations matching the trope, then deliver the opposite outcome").
6.3 Dual-Path AI Integration
ProseCreator implements two AI integration paths, each optimized for different use cases:
MageAgent (Multi-Agent Orchestration): A multi-agent consensus system where multiple specialized agents (up to 50 defined roles) deliberate on the generation task. This path produces higher-quality results through agent deliberation but requires 5--7 minutes per generation. It is used for complex tasks where quality justifies latency, such as master narrative analysis and character bible generation.
ClaudeDirectClient (Single-Agent Proxy): A direct connection to a Claude instance via the claude-code-proxy at port 3100. This path is stateless, supports streaming, and completes in 30--120 seconds. It serves as both the fast path for routine generation and the fallback when MageAgent is unavailable.
The system implements automatic failover: if MageAgent fails (timeout, error, or unavailability), the request is transparently retried via ClaudeDirectClient. This dual-path design provides resilience while allowing quality-latency tradeoffs to be made on a per-task basis.
6.4 AntiAIDetection: Fifteen-Technique Humanization
The AntiAIDetection module (922 lines at src/generation/AntiAIDetection.ts) applies fifteen humanization techniques sequentially to generated content, targeting less than 5% AI detection probability:
-
Vocabulary diversification: Replaces AI-typical words (delve, utilize, leverage, navigate, landscape, tapestry, meticulous, intricate, robust, paramount, testament, nuanced, multifaceted, realm, embark, unveil, unravel, epitome, quintessential, moreover, furthermore, additionally, thus, hence, therefore) with natural alternatives selected randomly from pools.
-
Sentence structure variation: Breaks the regularity of AI-generated sentence patterns by varying clause order, introducing inversions, and mixing simple with complex sentence structures.
-
Rhythm naturalization: Adjusts the prosodic rhythm of sentences to avoid the metronomic regularity characteristic of AI output.
-
Imperfection injection: Introduces controlled imperfections---minor stylistic quirks, sentence-level idiosyncrasies---that characterize authentic human writing.
-
Perplexity increase: Injects unexpected word choices and less predictable phrasings to raise the statistical perplexity of the text, which AI detectors use as a primary signal.
-
Burstiness enhancement: Introduces deliberate variation in sentence length distribution (burstiness), since AI text tends toward more uniform sentence lengths than human writing.
-
Transition variation: Replaces formulaic transitional phrases with more natural connective tissue.
-
Metaphor freshening: Identifies and replaces cliched or overly precise metaphors with more organic figurative language.
-
Dialogue naturalization: Makes dialogue more realistic through hesitations, interruptions, and the cognitive imprecision of spoken language.
-
Emotion authentication: Replaces declared emotions ("She felt terrified") with embodied emotional responses ("Her skin went wrong").
-
Dialogue tag diversification: Reduces over-reliance on "said" variations and adjusts tag placement and frequency.
-
Show-vs-tell optimization: Identifies telling statements and converts them to showing through action and sensory detail.
-
Sensory variation: Ensures sensory descriptions span multiple modalities rather than clustering in the visual.
-
Paragraph structure variation: Varies paragraph length and internal structure to avoid the regularity of AI-generated paragraphs.
-
Flow naturalization: Adjusts inter-sentence and inter-paragraph flow for more organic narrative movement.
Beyond these fifteen general techniques, the module implements twelve genre-specific profiles. Each profile defines target sentence length ranges, fragment rates, emotion rendering patterns (body-first sensations to use vs. emotional declarations to avoid), and vocabulary rules. For example:
- Thriller: Short target sentences (4--18 words), 15% fragment rate, body-first emotion ("hands too steady," "tunnel vision," "time slowed wrong"), replacement of "threat neutralized" with "he stopped moving."
- Horror: Very short sentences (3--20 words), 30% fragment rate, sensory wrongness patterns ("her skin went wrong," "something in her stomach that wasn't hunger"), avoidance of declaration words (terrifying, horrifying, frightening).
- Romance: Wide range (6--30 words), attraction rendered through action rather than labels ("she caught herself noticing," "moved slightly closer without deciding to"), avoidance of emotional shorthand (chemistry, drawn to, heart fluttered).
- Literary fiction: Maximum range (5--60 words), 12% fragment rate, form-as-meaning principle, deletion of empty intensifiers (profound, meaningful, resonant).
6.5 ContinuityValidator: Ten Parallel Validation Dimensions
The ContinuityValidator (at src/generation/ContinuityValidator.ts) validates generated content against the injected context across ten dimensions, all executed in parallel via Promise.all():
- Character presence: Validates that characters referenced in the generated content are consistent with those specified in the blueprint and present in the scene.
- Location consistency: Ensures the setting described in the generated content matches the location specified in the blueprint.
- Plot thread advancement: Verifies that active plot threads are advanced or maintained, and that no resolved threads are inadvertently reactivated.
- World rule enforcement: Checks that generated content does not violate established world rules (e.g., a character using magic in a setting where magic requires specific conditions).
- Timeline ordering: Validates temporal consistency, ensuring events occur in a logically possible order.
- Character state tracking: Verifies that character states (alive/dead, injured/healthy, location) are consistent with the most recent established state.
- Voice fingerprint matching: Compares character dialogue against established voice fingerprints stored in Qdrant.
- Tone consistency: Validates that the emotional tone of the generated content matches the blueprint's specification.
- Trope execution alignment: Ensures that trope executions in the generated content align with the assigned trope and its modifier.
- World element coherence: Checks that references to world-building elements (magic systems, technologies, cultural norms) are consistent with their established definitions.
The validator computes an overall continuity score using a weighted formula: critical issues reduce the score by 0.3, high-severity issues by 0.2, medium by 0.1, and low by 0.05. The target is a minimum score of 0.95 (95%).
6.6 VoiceConsistency: Eleven-Point Psychological Validation
The VoiceConsistency module (980 lines at src/generation/VoiceConsistency.ts) validates that character dialogue maintains psychological consistency with the established character profile. It performs eleven checks:
Base checks (always active):
- Vocabulary level: Does the dialogue's vocabulary match the character's education and background?
- Speech patterns: Are formality levels, contraction usage, and speech rhythms consistent?
- Emotional tone: Does the emotional coloring of dialogue match the character's current state?
- Sentence structure: Are sentence complexity and construction patterns consistent with prior dialogue?
- Formality level: Is the register appropriate for this character in this context?
Enhanced checks (activated when character bible with enhanced speech profile is available): 6. Dialect regional markers: Does the dialogue maintain dialect-specific vocabulary and grammar? 7. Speech impediment representation: Are established speech impediments consistently represented? 8. Code-switching/register shifts: Does the character appropriately shift between registers in different social contexts? 9. Verbal filler frequency: Are verbal fillers (um, like, you know) used at the frequency established for this character? 10. Emotional speech shift markers: Does the character's speech change in predictable ways under emotional stress?
Psychological check (activated when psychological profile is available): 11. Big Five personality integration: Does the dialogue reflect the character's established scores on Openness, Conscientiousness, Extraversion, Agreeableness, and Neuroticism?
Each check produces issues that feed into a similarity score calculation. The target similarity is 0.95 or above; scores below this threshold trigger suggestions for dialogue revision.
7. Story Architecture Features
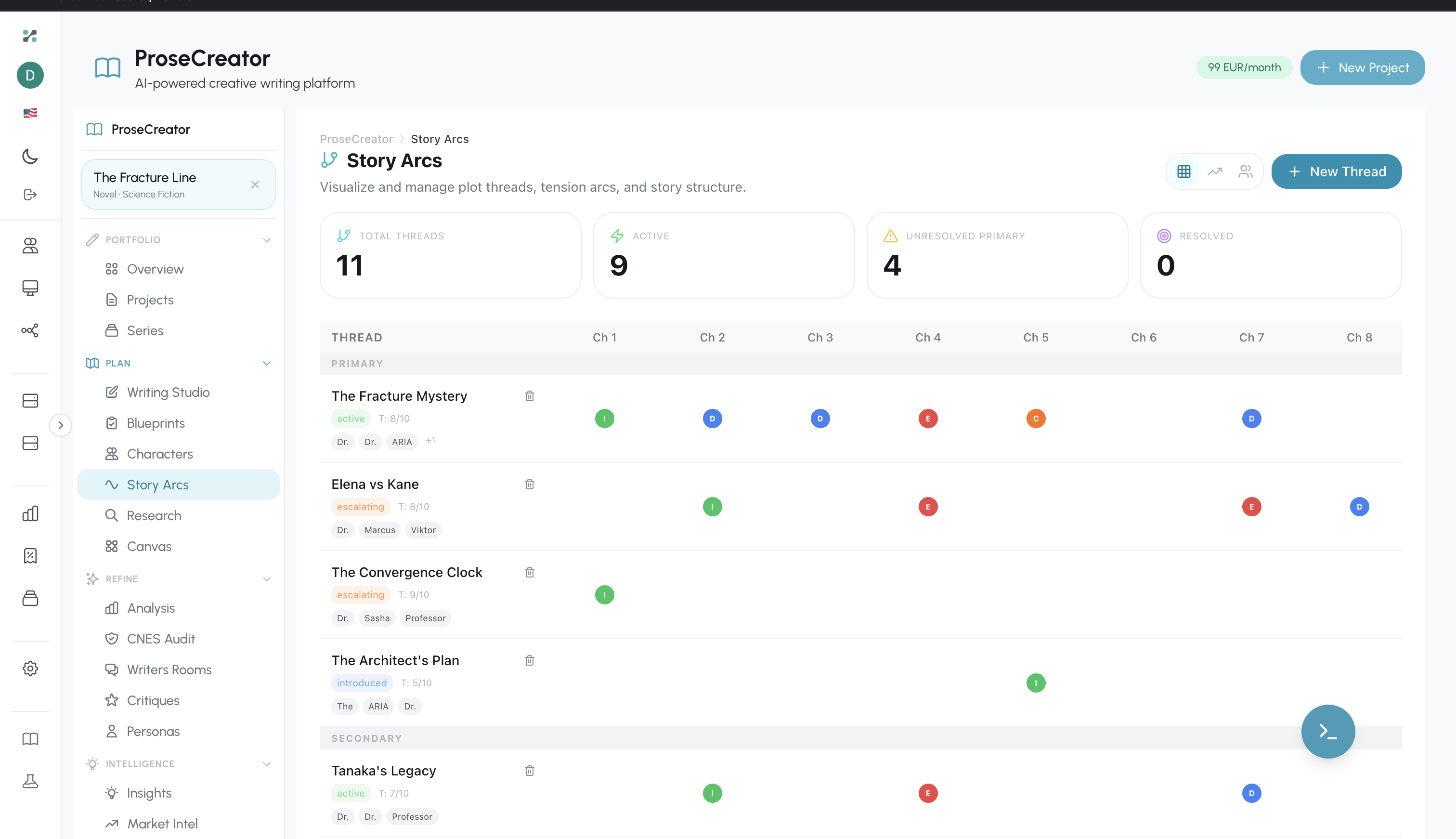 Figure 6. Story Arcs interface showing 11 plot threads tracked across 8 chapters with status indicators (active, introduced, developing) and character involvement tags.
Figure 6. Story Arcs interface showing 11 plot threads tracked across 8 chapters with status indicators (active, introduced, developing) and character involvement tags.
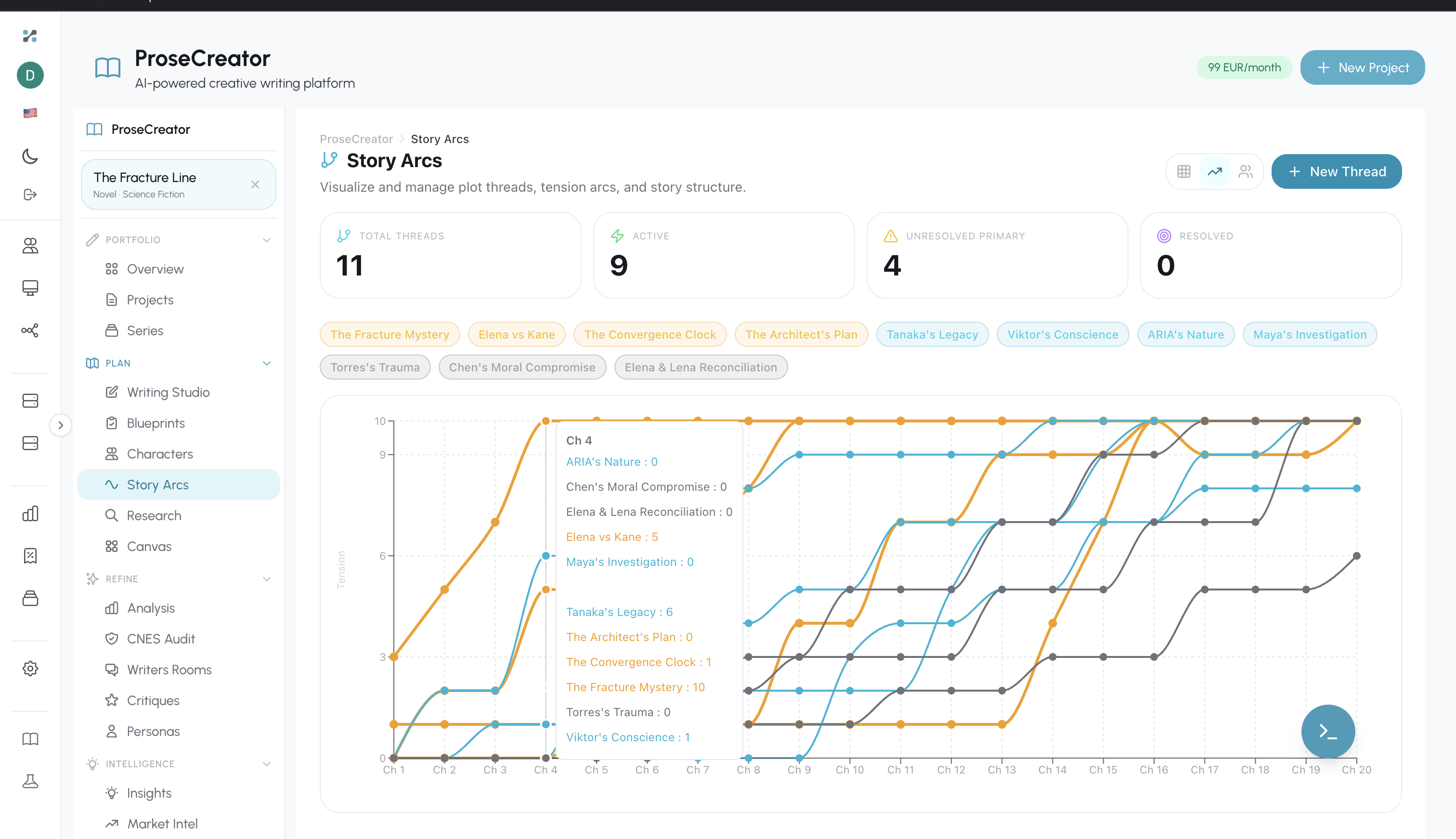 Figure 7. Story Arcs timeline visualization showing plot thread progression and tension curves across the manuscript timeline.
Figure 7. Story Arcs timeline visualization showing plot thread progression and tension curves across the manuscript timeline.
7.1 PlotThreadTracker
The PlotThreadTracker (at src/blueprint/PlotThreadTracker.ts) leverages Neo4j's graph traversal capabilities to manage plot thread dependencies and lifecycle states. Each plot thread follows a state machine: introduced → developing → active → resolved. Threads can also be marked as abandoned, triggering a narrative note about deliberate abandonment.
The DEVELOPS relationship in Neo4j captures dependency chains between threads---a subplot may develop from a main plot thread, and resolving the subplot may be a prerequisite for advancing the main thread. These dependency chains inform the ContextInjector's predictions about likely next developments and enable automated detection of "orphaned" threads that have been introduced but lost track of.
Foreshadowing elements are extracted from generated dialogue and description, stored as JSON arrays on the PlotThread node, and tracked for payoff. The system flags foreshadowing that has been dormant for more than a configurable number of chapters, surfacing it to the author as an insight.
7.2 Character Evolution Tracking
The character evolution system uses four relational tables (added in migrations 060--061) to track character development over time: evolution_snapshots (point-in-time character state captures), trait_scores (numerical scores for personality traits at each snapshot), belief_milestones (moments where a character's beliefs undergo significant change), and relationship_states (the state of each character relationship at each snapshot).
The CharacterEvolutionService performs AI-driven analysis of character evolution via ClaudeDirectClient, producing visualization data for five frontend components: emotional arc line charts, multi-phase radar charts with Act overlays showing trait evolution across story structure, belief evolution flow diagrams, before/after comparison panels, and enhanced timeline views.
This system enables the author to visualize whether their characters are developing in the intended direction and to catch "flat" characters whose traits remain static when they should be growing.
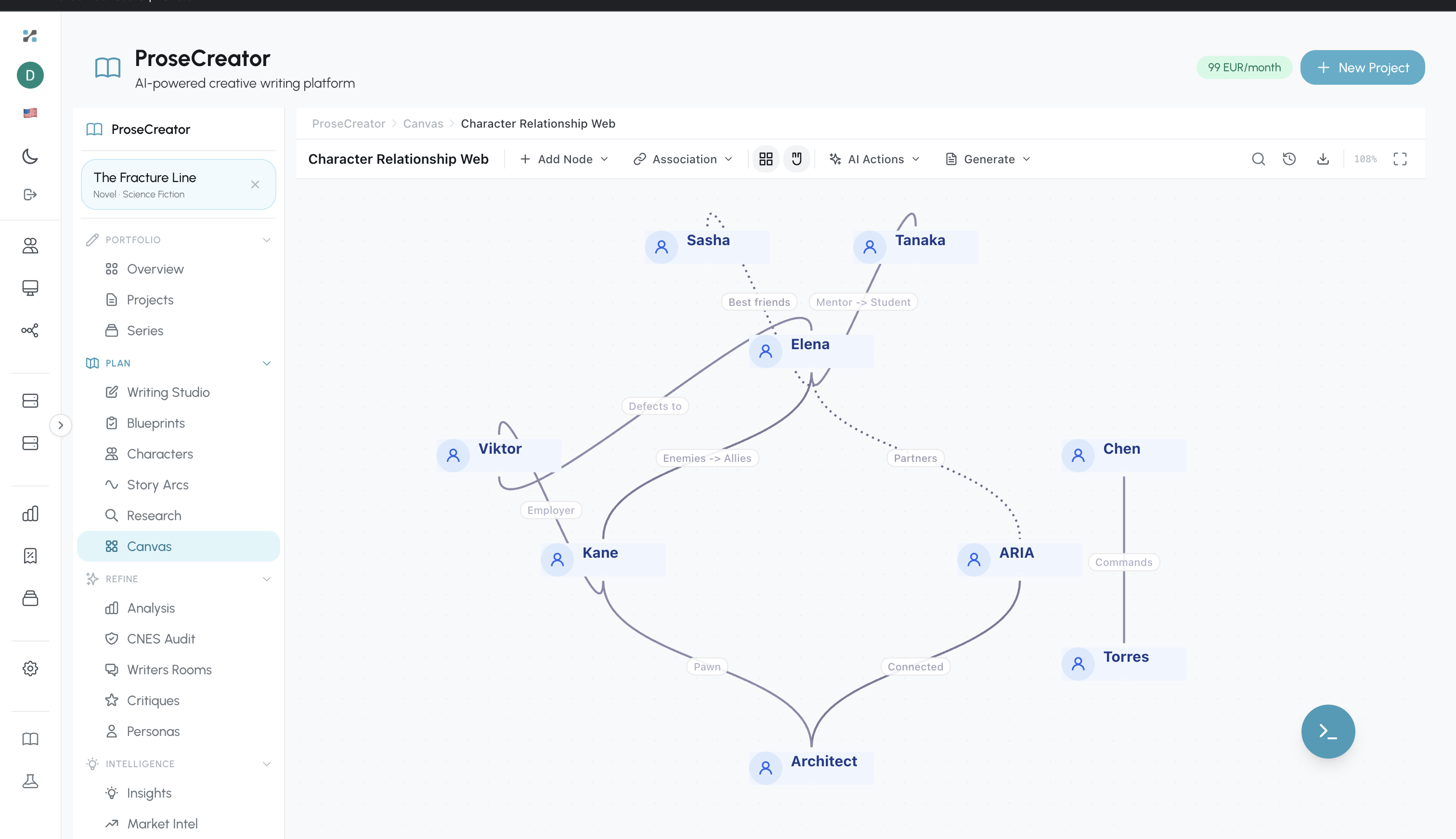 Figure 8. Canvas visualization showing the character relationship web for "The Fracture Line," with named characters, labeled relationship types (Best Friends, Mentor/Student, Enemies→Allies), and AI-assisted relationship analysis tools.
Figure 8. Canvas visualization showing the character relationship web for "The Fracture Line," with named characters, labeled relationship types (Best Friends, Mentor/Student, Enemies→Allies), and AI-assisted relationship analysis tools.
7.3 TropeService: Narrative Pattern Management
The TropeService manages a database of 136 seed tropes (established by migration data) that authors can assign to their projects. Each trope assignment specifies an execution modifier and target scope (beat-level or chapter-level). The eleven execution modifiers provide precise control over how a trope manifests:
- Played straight: The trope is used as conventionally expected.
- Subverted: Set up expectations then deliver the opposite.
- Deconstructed: Explore the realistic consequences of the trope.
- Lampshaded: Characters acknowledge the trope within the story.
- Invoked: Characters deliberately invoke the trope.
- Zigzagged: Alternately played straight and subverted.
- Exploited: Characters exploit knowledge of the trope.
- Justified: In-story explanation for why the trope applies.
- Reconstructed: After deconstruction, rebuild the trope with new meaning.
- Implied: The trope is suggested but never made explicit.
- Double subverted: Appears to be subverted, then turns out straight after all.
Each modifier generates specific LLM guidance injected into the generation prompt. Coverage analytics track what percentage of assigned tropes have been executed across the manuscript.
7.4 WorldBuildingService
The WorldBuildingService manages world-building elements as a Neo4j-backed graph with 15 element types (magic_system, natural_law, technology, religion, political_system, social_structure, economy, geography, ecology, language_system, art_tradition, military_doctrine, education_system, judicial_system, custom). Each element has an importance tier (critical, major, moderate, minor) that determines how aggressively it is injected into generation context.
Critical and major elements are retrieved by the ContextInjector and included in the generation prompt as hard constraints. The WorldBuildingService provides AI-powered consistency checking: when a new world element is added, the system checks it against existing elements for contradictions (e.g., a new technology that contradicts an established natural law).
7.5 Authenticity Markers
The authenticity markers system maintains a genre-specific database of human versus AI writing patterns. Each genre has rules weighted by severity (critical, high, medium, low) that encode the distinctive signatures of authentic human writing in that genre. These rules are stored in PostgreSQL (migration 090) and injected into generation prompts alongside the AntiAIDetection module's algorithmic humanization.
7.6 Constitutional AI for Creative Writing
The constitution system implements structured author intent through a six-section framework:
- Creative vision: The author's high-level artistic goals and thematic aspirations.
- Voice and tone: Desired narrative voice characteristics, tonal range, and stylistic preferences.
- Content rules: Hard constraints on content (e.g., "no graphic violence," "keep romantic content to PG-13").
- Legal compliance: Copyright and licensing constraints.
- Thematic guardrails: Themes to explore and themes to avoid.
- Style directives: Specific stylistic instructions (e.g., "use Oxford commas," "avoid em dashes").
Project-level constitutions apply to individual manuscripts; series-level constitutions apply across all books in a series. Constitutions are encoded as system prompt prefixes, making them stronger than per-beat instructions---the generation model treats them as foundational rules rather than suggestions.
8. Workflow Dispatch Architecture
8.1 Evolution from In-Process to External Dispatch
The original ProseCreator architecture processed all generation jobs in-process using a PostgreSQL-backed job queue (JobQueueProcessor) with FOR UPDATE SKIP LOCKED for concurrent job claiming. While functional, this design created a fundamental scalability bottleneck: job processing consumed the same CPU and memory resources as HTTP request handling, and horizontal scaling required complex coordination for job distribution.
The current architecture eliminates all in-process job state. The WorkflowJobDispatcher (619 lines at src/services/WorkflowJobDispatcher.ts) serves as the central dispatch point, routing every job to an external workflow execution engine (Nexus Workflows). The legacy JobQueueProcessor (7,082 lines) was deleted entirely in favor of this stateless dispatch model.
8.2 Two-Tier Execution Model
The dispatcher classifies each of the 48 job types into one of two execution tiers:
Tier 1: LLM-Only (13 types) --- These jobs run entirely within Nexus Workflows. The workflow engine gathers context, constructs prompts, calls the Claude proxy, parses the LLM output, and writes results to the database. ProseCreator polls for completion and runs optional post-processing callbacks.
Tier 1 job types include: research, research_refine, claim_validation, index_generation, publication_generate_copyright, publication_generate_about, publication_generate_blurb, publication_generate_matter, publication_readiness_ai, constitution_generate, constitution_generate_section, character_evolution_analysis, and tts_voice_profile.
Tier 2: Callback (35+ types) --- These jobs require access to ProseCreator's full ServiceContainer (52 repositories, ProseGenerator, BlueprintManager, etc.) for processing. Nexus Workflows triggers a callback to ProseCreator's /internal-jobs/:jobId/callback endpoint, where one of 15 job handlers processes the result with full access to all services.
Tier 2 job types include the core creative pipeline (beat, chapter, blueprint, analysis, critique, room_persona, character_bible), canvas operations (9 types), audiobook processing (4 types), forge pipeline (5 types), ingestion (4 types), and specialized handlers for tropes (3 types), world-building (4 types), and more.
The critical architectural insight is that request body format must match receiver expectations. A production bug (fixed in commit 75c3d26) revealed that the trigger endpoint expected req.body.payload wrapping, but the dispatcher was sending bare body data---causing inputParams to be silently lost on every Tier 2 callback. This class of integration error underscores the importance of end-to-end contract testing in distributed architectures.
8.3 Seven Logical Queues
Job types are distributed across seven logical queues within Nexus Workflows, enabling parallel execution without resource contention:
- prosecreator-generation: Core content creation (beat, chapter, blueprint, forge pipeline, world element generation)
- prosecreator-analysis: Inspectors, character bibles, critiques, room personas, trope analysis, TTS voice profiles
- prosecreator-publication: Front/back matter, constitution, readiness assessment
- prosecreator-research: Research generation, refinement, document-to-research, index generation
- prosecreator-audiobook: Full audiobook, chapter-level, assembly, export
- prosecreator-canvas: All nine canvas AI operations (suggest relationships, grouping, layout, enrichment, analysis, conversions)
- prosecreator-ingestion: Document ingestion, novel import, Substack import, batch monitoring
This queue architecture ensures that a spike in audiobook processing jobs, for example, does not block beat generation---each queue can be independently scaled by the workflow engine.
Figure 4 illustrates the complete workflow dispatch architecture.
 Figure 4. Two-tier workflow dispatch architecture with 48+ job types distributed across seven logical queues.
Figure 4. Two-tier workflow dispatch architecture with 48+ job types distributed across seven logical queues.
Figure 4b presents the end-to-end integration flow showing how the ProseCreator microservice, Adverant Nexus platform services, and the AI and data persistence layer interact across the numbered execution path. Where Figure 4 focuses on the two-tier dispatch mechanism, Figure 4b traces the complete lifecycle from job dispatch (step 1) through LLM prompting and webhook callbacks (steps 2a/2b), result persistence (step 3a), runtime skill instruction fetching (step 3b), content generation via the Skills Engine (step 4), and the triple-write to all three stores via the MemoryManager (step 5). Notably, the Nexus Skills Engine enables dynamic prompt injection---updating AI behavior through runtime skill instructions without requiring code deployments---while the tri-store MemoryManager ensures every generated entity is atomically written to PostgreSQL (relational state), Neo4j (graph relationships), and Qdrant (vector embeddings).
 Figure 4b. End-to-end integration flow across three architectural zones: ProseCreator microservice (stateless pods with 55 REST routes, WorkflowJobDispatcher, and 15 BaseJobHandlers), Adverant Nexus (Nexus Workflows engine with seven logical queues and the Skills Engine for dynamic prompt injection), and the AI and data persistence layer (Claude Proxy/MageAgent for multi-model generation and the tri-store memory combining PostgreSQL, Neo4j, and Qdrant).
Figure 4b. End-to-end integration flow across three architectural zones: ProseCreator microservice (stateless pods with 55 REST routes, WorkflowJobDispatcher, and 15 BaseJobHandlers), Adverant Nexus (Nexus Workflows engine with seven logical queues and the Skills Engine for dynamic prompt injection), and the AI and data persistence layer (Claude Proxy/MageAgent for multi-model generation and the tri-store memory combining PostgreSQL, Neo4j, and Qdrant).
8.4 Job Handler Architecture
Fifteen job handler classes process Tier 2 callbacks, each extending a BaseJobHandler that provides shared utilities:
- Constitution loading: Retrieving and formatting project/series constitutions for LLM context.
- Skill instruction fetching: Runtime retrieval of skill instructions from the Nexus Skills Engine API. Four registered skills (Room Feedback Implementer, Insight Resolver, World-Building AI Engine, Document-to-Research) provide specialized instructions that are injected into the LLM system prompt at runtime, enabling behavior updates without code deployment.
- JSON parsing: Robust extraction of structured data from LLM outputs, handling the common case where the model wraps JSON in markdown code fences.
- Error handling: Standardized error capture with job status updates.
The handlers are: ContentGenerationHandler, BlueprintHandler, AnalysisHandler, CharacterHandler, WritersRoomHandler, ResearchHandler, CanvasHandler, ConstitutionHandler, PublicationHandler, AudiobookHandler, TropeHandler, WorldBuildingHandler, ForgeHandler, DocumentHandler, and MiscHandler.
9. Horizontal Scalability Analysis
9.1 Stateless Pod Design
The most consequential architectural decision in ProseCreator's scalability story is the elimination of all in-process job state. With the migration from the in-process JobQueueProcessor to the external WorkflowJobDispatcher, ProseCreator pods maintain no generation state in memory. All state resides in external databases:
- Job status: PostgreSQL (
prose.generation_jobstable) - Story content: PostgreSQL + Neo4j + Qdrant
- Rate limits: Redis
- Semantic memory: GraphRAG API
This means any pod can handle any request---there is no session affinity requirement. Kubernetes Horizontal Pod Autoscaler (HPA) can scale pods based on CPU, memory, or custom metrics without concern for job distribution or state migration. A pod can be terminated at any time (receiving SIGTERM) and replaced by a new pod that immediately begins serving requests from the same shared state.
The graceful shutdown sequence ensures clean resource release: close WebSocket connections, stop editor sync service, drain database connection pools (PostgreSQL, Neo4j), and exit. The Tini init process ensures proper signal handling, preventing zombie processes that can accumulate in containerized environments.
9.2 External Job Queue for Spiky Workloads
Content generation is inherently spiky and long-running. A single beat generation takes 30--120 seconds via ClaudeDirectClient or 5--7 minutes via MageAgent. Chapter generation, which orchestrates multiple beat generations, can take 3--5 minutes. These durations would be devastating for request handling if executed in-process.
By routing all 48 job types to Nexus Workflows, ProseCreator decouples request handling from computation. The HTTP handler returns a job ID within milliseconds; the actual generation occurs asynchronously in the workflow engine. This architecture transforms the scaling problem: ProseCreator pods scale based on API request volume (lightweight), while the workflow engine scales independently based on job queue depth and LLM call concurrency.
The seven logical queues provide further isolation. A burst of audiobook export requests fills only the prosecreator-audiobook queue, leaving the generation queue unaffected. This prevents resource contention between qualitatively different workloads.
9.3 Multi-Database Scaling Strategy
Each database in the tri-store architecture can be scaled independently:
PostgreSQL: Read replicas handle the read-heavy query patterns typical of project listing, chapter browsing, and job status polling. Connection pooling uses configurable pool sizes with 10-second acquisition timeout and 30-second idle timeout, preventing connection exhaustion under load. Write operations (beat storage, job status updates) go to the primary.
Neo4j: The Causal Cluster deployment model provides read replicas for graph traversal queries. Connection pooling is configured for 50 concurrent sessions with 3-hour maximum lifetime and 60-second acquisition timeout. Graph queries are predominantly read operations (character relationship lookups, plot thread traversals), making read replicas highly effective.
Qdrant: As an HTTP-based service, Qdrant requires no client-side connection pooling. Horizontal sharding distributes vector collections across multiple nodes, with each shard handling a subset of the vector space. This is particularly effective because vector similarity searches are embarrassingly parallel across shards.
Redis: Cluster mode distributes rate limit counters across multiple Redis nodes. Since rate limiting is stateless from the application's perspective (each request independently checks and increments a counter), Redis cluster scaling is transparent to the ProseCreator application.
9.4 Connection Pooling Configuration
The connection pooling configuration reflects production-learned lessons about resource management:
PostgreSQL: configurable max pool | 10s acquisition timeout | 30s idle timeout
Neo4j: 50 concurrent | 3-hour max lifetime | 60s acquisition timeout
Qdrant: HTTP stateless (no pooling needed)
Redis: Shared counter backend for cross-pod rate limiting
The Neo4j pool's 3-hour maximum lifetime deserves explanation: Neo4j connections that remain open indefinitely can accumulate server-side state, leading to memory pressure on the Neo4j server. The 3-hour limit ensures connections are periodically recycled while remaining long enough to amortize connection establishment cost.
9.5 Multi-Tenant Isolation
Multi-tenant isolation is enforced at five independent levels:
-
PostgreSQL: Every query includes
WHERE user_id = $1orWHERE project_id = $1clauses, ensuring row-level isolation. Parameterized queries prevent SQL injection. -
Neo4j: All Cypher queries use parameterized inputs with user/project scoping. Graph nodes include
project_idproperties that are included inWHEREclauses. -
Qdrant: Every vector search includes payload tag filtering on
user_id, ensuring that similarity results only return vectors belonging to the requesting user's content. -
GraphRAG: HTTP headers (
X-App-ID: prosecreator+X-User-ID: <user_id>) scope all memory operations to the requesting user. The retrieval filter usesshould(OR) semantics for combining tenant criteria. -
WebSocket: JWT-scoped broadcast ensures that generation progress events are delivered only to the user's active connections. Room membership is tracked per-connection and cleaned up on disconnect.
9.6 Tier-Based Rate Limiting
Rate limiting is enforced at four service tiers:
| Tier | Projects | Words/Month | Series Books | Concurrent Jobs |
|---|---|---|---|---|
| Starter | 1 | 50,000 | 1 | 1 |
| Professional | 5 | 200,000 | 3 | 2 |
| Enterprise | Unlimited | 1,000,000 | Unlimited | 5 |
| Studio | Unlimited | Unlimited | Unlimited | 10 |
Rate limit counters are stored in Redis and shared across all ProseCreator pods, ensuring consistent enforcement regardless of which pod handles a request. The concurrent job limit prevents a single user from monopolizing the workflow engine's capacity.
9.7 WebSocket Scaling Considerations
WebSocket connections present a particular challenge for horizontal scaling. ProseCreator's current design maintains room membership in-process, meaning that WebSocket broadcast reaches only clients connected to the same pod. This is acceptable for the current deployment scale but would require modification for very large deployments.
The stateless design provides a natural mitigation: when a WebSocket connection drops (due to pod restart or network interruption), the client automatically reconnects to whichever pod the load balancer selects. Since all state is external, the reconnected client immediately has full context. A 30-second ping/pong keepalive prevents proxy idle timeouts from silently dropping connections.
For truly large scale, a Redis pub/sub or dedicated message broker could distribute WebSocket events across pods. This modification is straightforward given the existing Redis infrastructure but has not been necessary at the current deployment scale.
9.8 Kubernetes Deployment Configuration
The Kubernetes deployment configuration reflects production hardening:
- Tini init process: Ensures proper signal handling and zombie process reaping.
- Non-root user: Container runs as a non-root user for security.
- Health checks: Both readiness (
/prosecreator/api/health/ready) and liveness (/prosecreator/api/health/live) probes ensure traffic is only routed to healthy pods and unhealthy pods are restarted. - Resource limits: 100m--500m CPU and 256Mi--1Gi RAM per pod, providing predictable resource usage for capacity planning.
- Graceful shutdown: Configurable termination grace period allows in-flight requests to complete.
- Rolling updates: Zero-downtime deployments via Kubernetes rolling update strategy.
Figure 5 illustrates the complete horizontal scaling topology.
 Figure 5. Horizontal scaling topology showing stateless pod replication, external workflow queue, independent database scaling, five-level multi-tenant isolation, and tier-based rate limiting.
Figure 5. Horizontal scaling topology showing stateless pod replication, external workflow queue, independent database scaling, five-level multi-tenant isolation, and tier-based rate limiting.
10. Multi-Format Export Pipeline
ProseCreator supports twelve specialized format generators, each implementing format-specific conventions and output structure:
- Novel/Fiction: Standard prose with chapter breaks, scene separators, and front/back matter.
- Screenplay: Fountain format with Final Draft XML export, enforcing standard screenplay formatting (scene headings, action lines, character cues, dialogue, parentheticals, transitions).
- Poetry: Meter analysis, rhyme scheme detection, stress patterns, and stanza structure.
- Comic book: Panel descriptions, dialogue balloons, caption boxes, and visual direction.
- YouTube: Script optimization for audience retention, with hook structure, SEO metadata, and engagement markers.
- Podcast: Episode structure with host/guest cues, transition points, and ad break markers.
- Academic/Technical/How-to: Structured prose with section hierarchy, citation formatting, and terminology consistency.
- Speech/Stageplay: Performance-oriented formatting with delivery notes and stage directions.
The PublicationService handles the complete publication pipeline: EPUB3, PDF, and DOCX export with AI-generated front and back matter (copyright page, about the author, book blurb, acknowledgments). The GeminiCoverService generates AI book covers via Google's Gemini Flash model, producing professional-quality cover images that can be incorporated into EPUB and PDF exports.
Export operations support both synchronous (direct download) and asynchronous (background job with progress tracking) modes, with the choice depending on manuscript size and export complexity.
11. Evaluation and Comparative Analysis
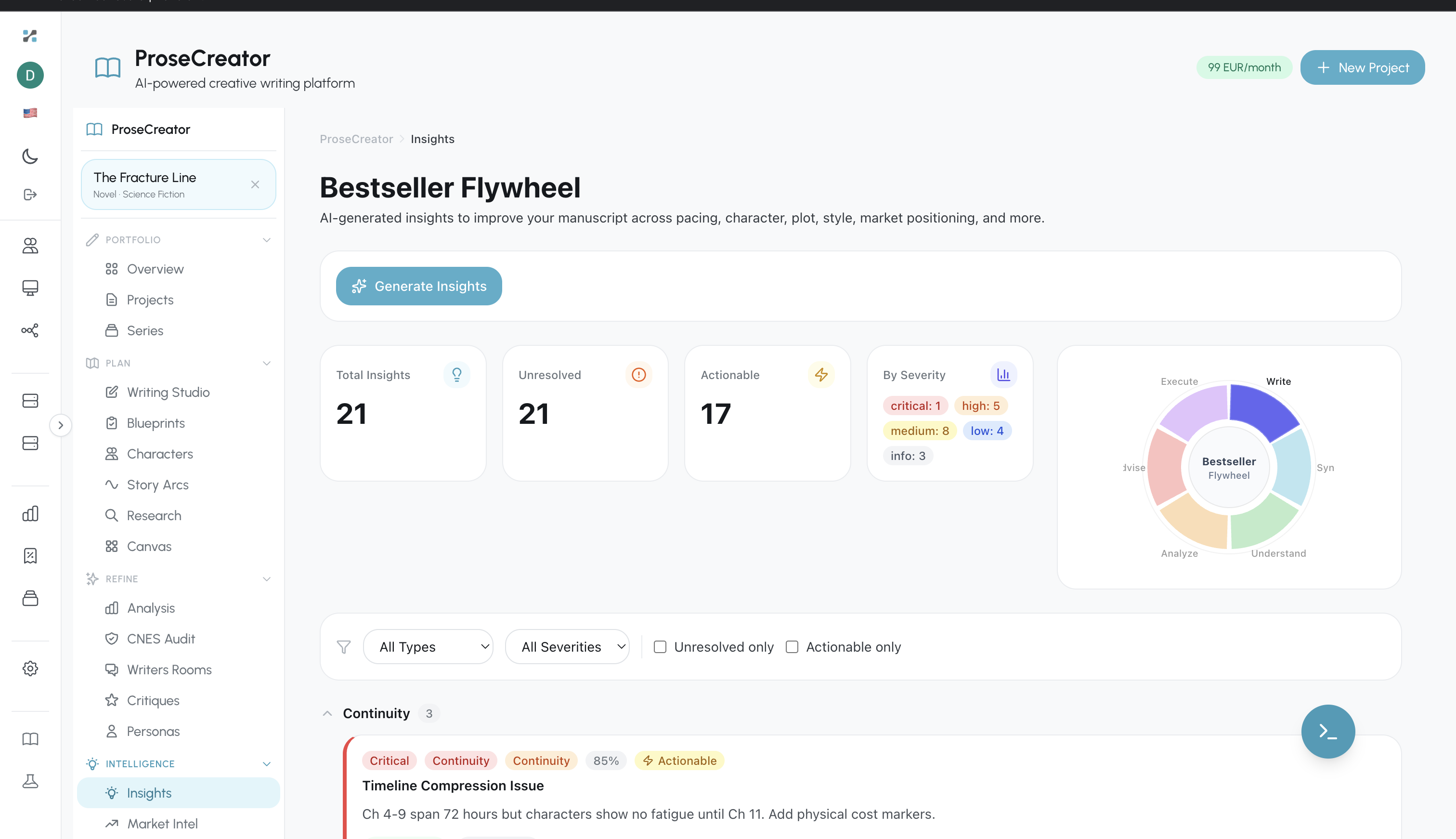 Figure 9. ProseCreator Insights dashboard showing the Bestseller Flywheel analysis --- 21 total insights across pacing, character, plot, style, and market positioning dimensions, with severity classification and actionable resolve/dismiss workflow.
Figure 9. ProseCreator Insights dashboard showing the Bestseller Flywheel analysis --- 21 total insights across pacing, character, plot, style, and market positioning dimensions, with severity classification and actionable resolve/dismiss workflow.
11.1 Feature Comparison
Table 1 presents a systematic comparison of ProseCreator against leading commercial AI writing tools across key architectural and feature dimensions.
Table 1: Feature Comparison of AI Writing Platforms
| Feature | ProseCreator | Sudowrite | NovelAI | Jasper | Writesonic |
|---|---|---|---|---|---|
| Context injection layers | 9 parallel | 2-3 | 1-2 | 1 | 1 |
| Continuity validation dimensions | 10 parallel | 0 | 0 | 0 | 0 |
| Voice consistency checks | 11 psychological | 3-4 | 2-3 | 0 | 0 |
| Output format generators | 12 specialized | 2 | 1 | 5 | 3 |
| Knowledge graph (Neo4j) | Yes (10 nodes, 16 rels) | No | No | No | No |
| Vector search (Qdrant) | Yes (4 collections) | Partial | No | No | No |
| Semantic memory (GraphRAG) | Yes (4 stacks) | No | No | No | No |
| Cross-book coherence | 1M+ words, 10+ books | Limited | No | No | No |
| Anti-AI detection techniques | 15 + 12 genre profiles | Unknown | No | No | No |
| Living blueprint evolution | Yes (6 categories) | No | No | No | No |
| World rule enforcement | Graph + semantic hybrid | No | No | No | No |
| Trope management | 136 tropes, 11 modifiers | No | No | No | No |
| Job types | 48+ across 7 queues | Unknown | Unknown | Unknown | Unknown |
| Multi-tenant isolation levels | 5 independent | 1-2 | 1 | 2 | 1-2 |
| Character evolution tracking | 4 relational tables + AI | Basic | No | No | No |
| Constitutional AI | 6-section framework | No | No | No | No |
| Series intelligence | Yes | Limited | No | No | No |
| Publication pipeline | EPUB3/PDF/DOCX + covers | DOCX | No | DOCX | DOCX |
A few caveats attend this comparison. Sudowrite's internal architecture is not publicly documented, so our assessment is based on externally observable capabilities. NovelAI's fine-tuned Kayra model may incorporate internal coherence mechanisms not visible to users. Jasper and Writesonic are primarily designed for marketing content rather than narrative fiction, making the comparison somewhat asymmetric.
11.2 Quantifiable System Metrics
Based on the production deployment and codebase analysis, we report the following system metrics:
- Context assembly latency: Target <500ms via 9-layer parallel retrieval with
Promise.all(). - Continuity validation: 10 dimensions checked in parallel; target score >= 0.95.
- Voice consistency: 11 psychological dimensions; target similarity >= 0.95.
- AI detection target: <5% via 15 general techniques + 12 genre-specific profiles.
- Cross-book coherence: Series intelligence handles 1M+ words across 10+ books with <2s retrieval.
- Job dispatch: 48+ types across 7 logical queues; zero in-process state.
- API surface: 55 REST route modules; Zod validation on all inputs.
- Database schema: 91+ PostgreSQL tables across 94 migrations.
- Graph schema: 10 Neo4j node types, 16 relationship types.
- Vector collections: 4 Qdrant collections (1536d, 1024d, 768d, 768d).
- Repository layer: 52 typed PostgreSQL repositories.
- Service layer: 41 business services; 15 job handlers.
- Format generators: 12 specialized output formatters.
- DI container: ServiceContainer manages 100+ components with dependency-ordered initialization.
These metrics represent architectural capacity rather than user-facing benchmarks. A formal user study measuring perceived narrative coherence, voice consistency, and AI detection rates in generated manuscripts remains future work.
11.3 Architectural Validation
Several architectural decisions have been validated through production deployment:
Tri-store superiority over single-store: The combination of relational, graph, and vector storage enables retrieval strategies that no single store can provide. A question like "find all scenes where Elena and Marcus interact, ordered by emotional intensity, with similar scenes from earlier in the manuscript" requires PostgreSQL for scene retrieval, Neo4j for relationship traversal (KNOWS relationship between Elena and Marcus), Qdrant for emotional intensity similarity, and GraphRAG for semantic matching of "similar scenes." No single store handles this query efficiently.
External job dispatch validation: The elimination of the 7,082-line JobQueueProcessor in favor of the 619-line WorkflowJobDispatcher represents a dramatic simplification. More importantly, it resolved a class of production issues related to in-process job state: stale jobs, zombie processes, and resource contention between job execution and request handling. The seven-queue architecture has eliminated cross-queue resource contention entirely.
Living blueprint utility: The blueprint evolution system has proven its value in scenarios where authors make significant narrative changes mid-manuscript. Without automatic blueprint evolution, the divergence between plan and reality grows monotonically, rendering the blueprint useless within a few chapters. With the evolver, the blueprint remains a useful guide even as the story develops in unexpected directions.
12. Discussion
12.1 Limitations
Several limitations warrant honest discussion.
Evaluation methodology: We have not conducted a formal user study comparing ProseCreator's output quality against competing systems. The feature comparison in Section 11 is based on architectural capabilities rather than measured outcomes. A controlled study measuring perceived coherence, voice consistency, and detection rates across systems would significantly strengthen the evaluation.
Neo4j as potential bottleneck: Graph traversal queries can become expensive for very large story worlds with thousands of nodes and complex relationship patterns. While the current connection pool (50 concurrent sessions) handles production load, a story world with, say, 500 characters each with 20 relationships would generate graph queries of significant complexity. Neo4j's Causal Cluster with read replicas mitigates this, but the fundamental complexity of graph traversal remains a concern at extreme scale.
WebSocket cross-pod coordination: The current in-process WebSocket room membership means that clients connected to different pods do not share real-time events. This is acceptable for single-user workflows but would become problematic for collaborative editing scenarios where multiple users work on the same manuscript simultaneously.
Context window limitations: The 8,000-token context budget, while sufficient for most generation scenarios, may be insufficient for particularly complex scenes involving many characters, active plot threads, and world-building constraints simultaneously. The smart truncation system handles overflow gracefully but necessarily discards some context information.
AI detection is an arms race: The humanization techniques described in Section 6.4 are effective against current-generation detectors, but detection technology continues to advance. Our algorithmic approach (vocabulary substitution, burstiness injection, etc.) may not remain effective against future statistical detectors that learn to recognize these specific humanization patterns.
12.2 Honest Assessment of Scale Claims
The series intelligence system's claim of handling "1M+ words across 10+ books" is an architectural design target backed by the parallel retrieval architecture (targeting <2s for 10 books). However, it has not been validated with a real 10-book series at production scale. The retrieval latency target assumes efficient Neo4j indexing and GraphRAG query performance; actual latency could exceed 2 seconds for series with complex cross-book relationship structures.
Similarly, the <500ms context injection target has been observed in development and staging environments but may vary in production under load, particularly if the Neo4j or Qdrant instances are under concurrent pressure from other services in the Nexus platform.
12.3 Performance Under Extreme Load
The stateless pod design theoretically supports unbounded horizontal scaling, but practical limits exist. Each pod opens connection pools to four databases, and each database has finite connection capacity. With 50-connection Neo4j pools per pod, 10 pods would require 500 Neo4j connections---approaching limits for many Neo4j deployments. Connection pooling configuration must be tuned in concert with the number of pods.
The external workflow engine (Nexus Workflows) becomes a bottleneck if its capacity is exhausted. Each generation job occupies a workflow worker for 30--300 seconds, limiting throughput to (workers / average_job_duration) jobs per second. Queue-based backpressure prevents system overload but introduces user-facing latency when queues are deep.
13. Conclusion and Future Work
We have presented ProseCreator, a production-deployed platform for AI-assisted creative writing that addresses the fundamental challenge of maintaining narrative coherence at novel and series scale. The tri-store knowledge architecture combining PostgreSQL, Neo4j, and Qdrant with a GraphRAG semantic layer provides the structured, queryable knowledge that long-form creative writing demands. The nine-layer parallel context injection pipeline, ten-dimensional continuity validation framework, and eleven-point voice consistency checker together ensure that generated content respects established narrative facts, character psychology, and story structure.
The living blueprint system solves the problem of plan-reality divergence that plagues outline-based generation approaches. The two-tier workflow dispatch architecture with seven logical queues enables horizontally scalable deployment without in-process job state, and the fifteen-technique humanization pipeline with twelve genre-specific profiles addresses the practical concern of AI-generated content detection.
Several directions for future work present themselves:
Formal user evaluation: A controlled study comparing ProseCreator's output quality against competing systems, measuring perceived coherence, voice consistency, and AI detection rates across multiple genres and manuscript lengths.
Collaborative editing: Extending the architecture to support multiple simultaneous authors working on the same manuscript, requiring cross-pod WebSocket event distribution and conflict resolution for concurrent edits.
Fine-tuned domain models: Training genre-specific language models on curated corpora to replace or augment general-purpose models, potentially improving both prose quality and generation speed.
Adaptive context budgeting: Dynamically adjusting the context token budget based on scene complexity rather than using a fixed 8,000-token limit, allocating more context to complex multi-character scenes and less to simpler passages.
Causal reasoning for continuity: Extending the ContinuityEngine beyond pattern-matching to causal reasoning, enabling detection of subtle logical inconsistencies that pattern matching cannot catch (e.g., a character making a decision based on information they have not yet learned).
Federated series intelligence: Distributing series memory across multiple GraphRAG instances for series exceeding the capacity of a single instance, with cross-instance retrieval coordination.
The growing sophistication of AI writing tools raises important questions about authorship, creativity, and the nature of human-AI collaboration in creative work. ProseCreator's architecture is deliberately designed to augment human creativity rather than replace it: the constitutional AI framework preserves author intent, the living blueprint respects narrative evolution, and the voice consistency system enforces the author's established character voices rather than imposing its own. The goal is not to write novels automatically but to give human authors the structural support they need to write better novels with AI assistance.
References
1. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., and Polosukhin, I. (2017). "Attention Is All You Need." *Advances in Neural Information Processing Systems (NeurIPS)*, 30. arXiv:1706.03762.
2. Yuan, A., Coenen, A., Reif, E., and Ippolito, D. (2022). "Wordcraft: Story Writing With Large Language Models." In *Proceedings of the 27th International Conference on Intelligent User Interfaces (IUI '22)*, pp. 841--852. ACM. doi:10.1145/3490099.3511105.
3. Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Kuttler, H., Lewis, M., Yih, W., Rocktaschel, T., Riedel, S., and Kiela, D. (2020). "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks." In *Proceedings of the 34th International Conference on Neural Information Processing Systems (NeurIPS)*, 33, pp. 9459--9474. arXiv:2005.11401.
4. Wang, J. and Hu, J. (2024). "Generating Long-form Story Using Dynamic Hierarchical Outlining with Memory-Enhancement." In *Proceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-Long)*. arXiv:2412.13575.
5. Guan, M. et al. (2025). "Guiding Generative Storytelling with Knowledge Graphs." arXiv:2505.24803.
6. SCORE: Story Coherence and Retrieval Enhancement for AI Narratives. (2025). arXiv:2503.23512.
7. Zhang, Y., Du, Y., Huang, Y., Chen, J., Wan, Y., and Huang, S. (2025). "Multi-Agent Collaboration Mechanisms: A Survey of LLMs." arXiv:2501.06322.
8. Brahman, F., Petrusca, A., and Chaturvedi, S. (2021). "Guiding Neural Story Generation with Reader Models." arXiv:2112.08596.
9. Li, S., Yu, J., and Li, Q. (2023). "Narrative Graph: Telling Evolving Stories Based on Event-centric Temporal Knowledge Graph." *Journal of Systems Science and Systems Engineering*, 32, pp. 206--225. doi:10.1007/s11518-023-5561-0.
10. Shi, Z., Wang, Y., Yin, F., Chen, X., Chang, K., and Hsieh, C. (2024). "Humanizing Machine-Generated Content: Evading AI-Text Detection through Adversarial Attack." In *Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING)*. arXiv:2404.01907.
11. Yang, Z., Reid, S., Gonzalez, E., and Klein, D. (2023). "DOC: Improving Long Story Coherence With Detailed Outline Control." In *Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL)*.
12. Multi-Agent Based Character Simulation for Story Writing. (2025). In *Proceedings of the 2nd Workshop on Intelligent and Interactive Writing Assistants (In2Writing), ACL 2025*.
13. Zhao, M. et al. (2025). "Measuring Information Distortion in Hierarchical Ultra Long Novel Generation: The Optimal Expansion Ratio." arXiv:2505.12572.
14. A Multi-Agent Framework for Long Story Generation. (2025). arXiv:2506.16445.
15. He, X. et al. (2024). "Evaluating Creative Short Story Generation in Humans and Large Language Models." arXiv:2411.02316.
16. Nguyen, T. and Yeom, H. (2020). "Horizontal Pod Autoscaling in Kubernetes for Elastic Container Orchestration." *Sensors*, 20(16), 4621. doi:10.3390/s20164621.
17. Lettria Case Study. (2024). "GraphRAG: How Lettria Unlocked 20% Accuracy Gains with Qdrant and Neo4j." Qdrant Technical Blog.
18. Burns, B., Grant, B., Oppenheimer, D., Brewer, E., and Wilkes, J. (2016). "Borg, Omega, and Kubernetes." *ACM Queue*, 14(1), pp. 70--93. doi:10.1145/2898442.2898444.
19. Kratzwald, B. and Feuerriegel, S. (2024). "On the Creativity of Large Language Models." *AI & Society*. doi:10.1007/s00146-024-02127-3.
20. Long Story Generation via Knowledge Graph and Literary Theory. (2025). arXiv:2508.03137.
21. Context-Preserving Gradient Modulation for Large Language Models: A Novel Approach to Semantic Consistency in Long-Form Text Generation. (2025). arXiv:2502.03643.
22. Kovavc, G. et al. (2024). "Tuning a Kubernetes Horizontal Pod Autoscaler for Meeting Performance and Load Demands in Cloud Deployments." *Applied Sciences*, 14(2), 646. doi:10.3390/app14020646.
---
This paper describes a production-deployed system. All architectural claims are grounded in the actual codebase of ProseCreator as of March 2026. The source code for the platform is proprietary. Specific file paths, line counts, and code-level details referenced throughout the paper can be verified against the ProseCreator repository.